Gradient Estimation: Training What You Can't Backprop Through
Introduction
Neural networks work well through the magic of backpropagation, but there are times when we can’t backpropagate through our layers. Let’s imagine we have a simple problem: We have a Mixture of Experts (MoE) model with a probabilistic routing layer.
To be specific, our routing layer selects one expert to route its computation through.
Our router is a simple linear projection and softmax that takes in our input vector $x \in \mathbb{R}^d$ to produce probability distribution over three experts.
Mathematically, we express this as $p = \text{softmax}(x W_r)$, where $W_r \in \mathbb{R}^{d \times k}$ is our routing matrix. We can sample from this distribution to get a single expert to route to ($i \sim p$), before running the rest of our network as usual ($l_{out} = \text{Expert}_i(x)$).
We have:
- Logits: The input
xpasses through a linear layer to produce logits $l$ for each expert.
- Probabilities: The logits are converted to probabilities using softmax.
- Sampling: An expert index
iis sampled from the calculated multinomial distribution with probabilitiesp.
- One-Hot Encoding: We represent the chosen expert
ias a one-hot vectory, where the $i$-th element is 1 and the rest are 0.
- Routing: We compute the output of our layer as $l_{out} = \text{Expert}_i (x)$. Mathematically, this is equal to:
Note that there’s a slight mathematical sleight-of-hand here to simplify the STE conceptualization for later on.
Our router normally indexes the expert list to pick one selected expert. Here, I write this as taking the dot product of the one-hot indexing vector with the vector of outputs from all the experts. Effectively, activating all the experts and throwing away all of the outputs except for the one chosen (dot-producting with a one-hot vector) is the same as activating a single expert.
Let’s visualize this computational flow:
This graph mirrors the sequential math operations outlined above, and I’ve highlighted the nondifferentiable operations in red. Now the problem becomes clear: during the backwards pass, how do we update our routing layer?
The chain rule gives us:
\[\underset{Routing\ Gradient}{\frac{\partial L}{\partial p}} = \left[\underset{\text{Incoming Gradient}}{\frac{\partial L}{\partial y}} \right] \left[\underset{\text{Local Gradient}}{\frac{\partial y}{\partial p}}\right]\]The issue arises when we try to compute $\frac{\partial y}{\partial p}$. We don’t know whether to upweight or downweight the probability of selecting the expert we selected, as we have no way of computing the counterfactual performance of selecting the other experts. Indeed, torch’s multinomial has no gradient; if we selected our expert using argmax or any other sampling method, we would face the same problem.
If we write out our code in Pytorch and visualize the autograd graph, we can validate that there’s no gradient flow to our routing weights.
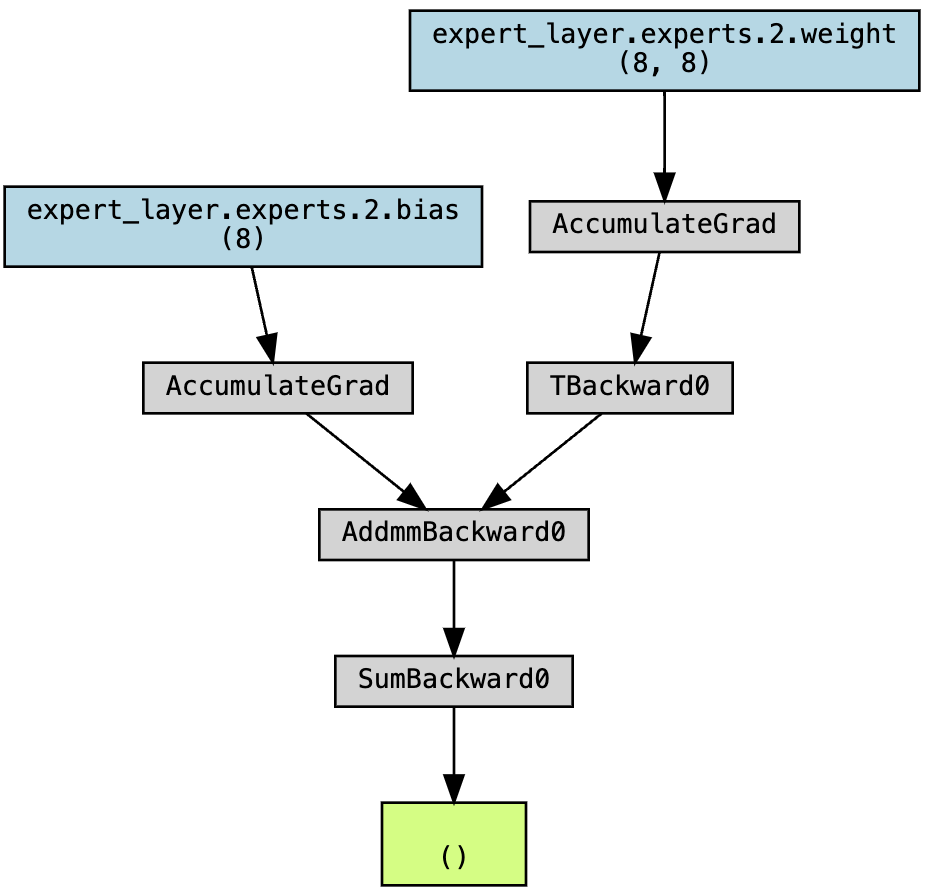
Note that there’s no gradient flow to any blocks with the name prefix routing_layer. For what the autograd compute graph should look like if the routing layer were trainable, see below.
The backprop hack
In the literature, there are a few ways we can backprop through non-differentiable operations. Most of them introduce a surrogate gradient that provides some learning signal and pushes the parameters of the non-differentiable operation in the right direction, and is what we’ll explore for the rest of this post. In the chain rule, the surrogate gradient replaces the local gradient (which is uncomputable). As a whole, this field is called gradient estimation.
Without going too far into the field, here are a few gradient estimation methods:
- Straight-Through Estimators (STEs): We pretend that the non-differentiable operation is the identity function during the backwards pass. It’s called “straight-through” because we pass straight through the non-differentiable operations (the three blocks in red above) as if they were not there. In this case, we’d approximate:
- REINFORCE: We conduct reinforcement learning on the troublesome operation. As you may expect from RL, this gradient estimator is high-variance and can explode your model during training if not properly handled.
-
Gumbel-Softmax: I’ll cover more on this in another post. This is a biased gradient estimator for argmax that empirically works very well, with the bias-variance tradeoff being tunable via temperature.
-
Custom estimators: For every common non-differentiable operation, there are tons of papers proposing different functions as gradient estimators. Recent research suggests that the straight-through estimator is approximately as good as any alternative, so try an STE baseline before you go custom.
STEs
Let’s just pretend that the local non-differentiable gradient is 1:
\[\left[\underset{\text{Local Gradient}}{\frac{\partial y}{\partial p}}\right] \approx 1\]Such that:
\[\underset{\text{Routing Gradient}}{\frac{\partial L}{\partial p}} = \underset{\text{Incoming Gradient}}{\frac{\partial L}{\partial y}}\]Given how simple this estimation is, does it work?
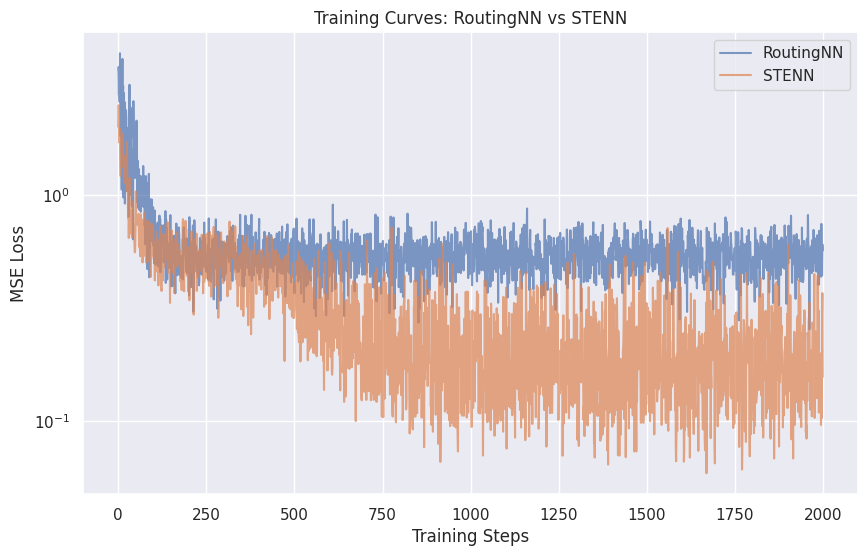
RoutingNN is our routing model defined in the above computational graph, and STENN is the same routing model + STE trick.
Yes.
To test this out, I wrote a bunch of code that compares the routing layer above and the routing layer with the STE trick in learning this linear piecewise function:
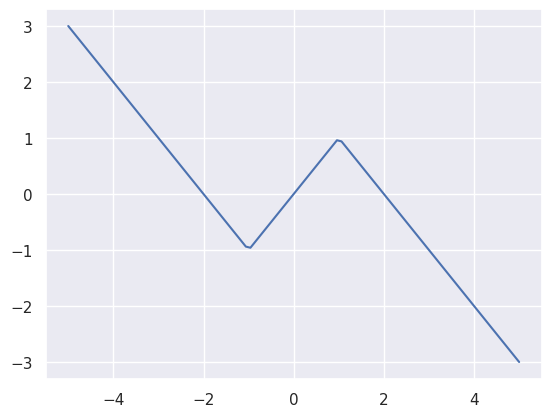
In this setup I have three experts, and each expert is a 1x1 linear projection. To learn this shape, the routing layer will need to route to the linear projection that corresponds to the right piece of the function.
The STE trick successfully guides the routing layer in modeling the triangular function:
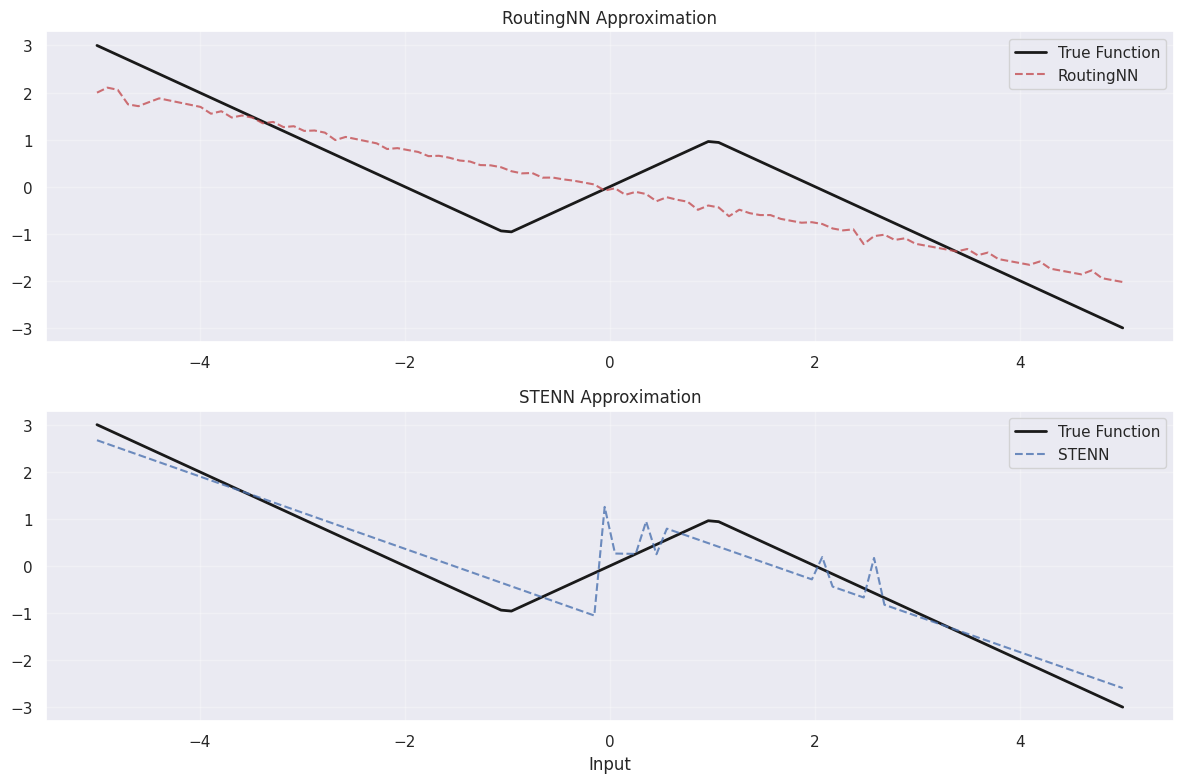
At first glance, this appears strange. We apply a surrogate gradient to the backwards pass, causing the computed gradients to no longer be the true directions of steepest descent of the loss landscape. While the reason we must apply a surrogate gradient is because we have a nondifferentiable operation in our forwards pass (i.e it’s unsurprising that the gradient estimation approach outperforms an approach that leaves the non-differentiable layer unlearnable), the wide success of gradient estimation for SOTA models across domains is surprising.
Straight Through estimator is a magic door between cont/discrete. If people really cracked it at scale for 1.58 bits models, might be useful for all kinds of wild applications.
— Sasha Rush (@srush_nlp) April 1, 2024
Imagine we’re descending down a loss landscape. Instead of going in the direction that slopes steepest downhill, we check our GPS, which contains a totally different heightmap. Then we take a step in the downhill direction on the GPS map, which could mean in reality taking a step orthogonal to the slope or uphill.
The bias in the gradient estimator also affects all layers prior to the non-differentiable operation, as the surrogate gradient is part of their gradient flow as per the chain rule. This surrogate loss landscape must have some nice properties indeed such that the surrogate gradient direction matches the true one - if not in magnitude, then in direction.
What does the loss landscape look like?
The Loss Landscape
It’s difficult to compute the surrogate loss landscape, since we only interact with it via its gradient (and analytical integration methods terrify me). But we can still visualize the surrogate update steps we’d be taking at each point in the true loss landscape. Here, I’ve sampled a bunch of points on the loss landscape to form a surface and calculated the surrogate gradient (the little white cones).
While the surrogate gradient differs significantly from the true gradient, following the surrogate gradient (in this case) still yields convergence to the same minima.
This is a surprising empirical result and scales well, being used in modern VQ-VAEs and MoEs of billions of parameters. Theory has followed and yielded some justifications for STE’s efficacy.
Liu et al. 2023 prove that the STE, in expectation, is identical to the first-degree Taylor approximation of the true gradient:
\[E[\hat{\nabla}_{ST}] = \hat{\nabla}_{1st-order}\]In our formulation, this would refer to:
\[E[\nabla_{i} L] = \nabla_p L_{1st-order}\]or:
\[E\left[\frac{\partial L}{\partial p}\right] = \text{1st-order}\left(\frac{\partial L}{\partial y}\right)\]Which implies that, in expectation, the gradients of the elements prior to the routing layer should at least have the same sign as the real gradient.
For their proof, see Appendix A of their paper.
Conclusion
The STE is a surprisingly robust approach for backpropagating through nondifferentiable functions. Have a stochastic variable in your neural network? No problem. In the backwards pass, pretend as if its gradient is the identity. Funnily enough, even Bengio called it a “heuristic method” when he reviewed it in 2013:
A fourth approach heuristically copies the gradient with respect to the stochastic output directly as an estimator of the gradient with respect to the sigmoid argument (we call this the straight-through estimator).
Modern works show that the STE is surprisingly robust, and works well when applied naively to a large variety of methods. While other gradient estimators expand upon STEs, they’re a simple and theory-backed baseline that we’ll build off (hopefully in similar posts in the future).
Note that the way I’ve formulated STEs allows it to be applied to random categorical variables. Using it for deterministic non-differentiable operations (e.g argmax) requires a bit more finesse, which I’ll discuss in the next post with Gumbel-Softmax.

yum.